파이썬 오디오 라이브러리 Top 5종 (Python Audio Library )

[관련 글]
2022.05.24 - [개발 이야기/Python] - [코딩 테스트] 파이썬 코딩테스트 핵심 요약 (CheatSheet) - 코테 1시간전에 꼭 보자.
2022.05.08 - [개발 이야기/Python] - [음성인식 - 6라인] 가장 쉬운 음성인식 (STT) 해 보기
2022.04.30 - [개발 이야기] - [코테] 코딩 테스트 플랫폼 4종 - 백준, 리트코드, 프로그래머스, 코드시그널
2020.12.16 - [분류 전체보기] - [개발] 피보나치(Fibonacci) 수열 구현 7가지 방법 - 파이썬 실습/확인 바로하기
2020.05.09 - [개발 이야기] - [개발] 파이썬 문법 5분만에 읽히기 - 파이썬 기본 문법 요약/정리 8 가지
2018.03.03 - [개발 이야기/Python] - 피보나치(Fibonacci) 수열을 구현하는 7가지 방법 - 파이썬(Python) 피보나치 구현 7선
0. IPython.display.Audio
우선, Jupyter Notebook 등에서 audio파일을 출력하기 위한 Ipython 내장 라이브러리 이다. IPython.display.Audio를 이용하여 audio파일을 Jupyter notebook에서 바로 출력하고, 테스트 할 수 있다.
import IPython.display as ipd
ipd.Audio('test.wav') # load a local WAV file
더욱이 훌륭한 점은 Memory에 있는 Array 개체도 바로 Sound로 출력할 수 있다는 점입니다.
따라서, 사운드 파일을 로드해서 전처리/가공 후에 결과를 출력해서 바로 바로 확인 할 수 있습니다.
import numpy
sr = 22050 # sample rate
T = 2.0 # seconds
t = numpy.linspace(0, T, int(T*sr), endpoint=False) # time variable
x = 0.5*numpy.sin(2*numpy.pi*440*t) # pure sine wave at 440 Hz
ipd.Audio(x, rate=sr) # load a NumPy array
또한, 아래와 같이 URL로 입력할 경우에는 다운로드를 먼저 진행 후 출력하게 된다. URL로 입력된 경우, Requests를 사용 해야하나? 라는 고민을 덜어 낼 수 있다.
ipd.Audio("http://www.nch.com.au/acm/8k16bitpcm.wav")결과에 대한 저장 등은 다음에 소개 드릴 Librosa, soundfile 등으로 진행하면 됩니다.
1. Surfboard
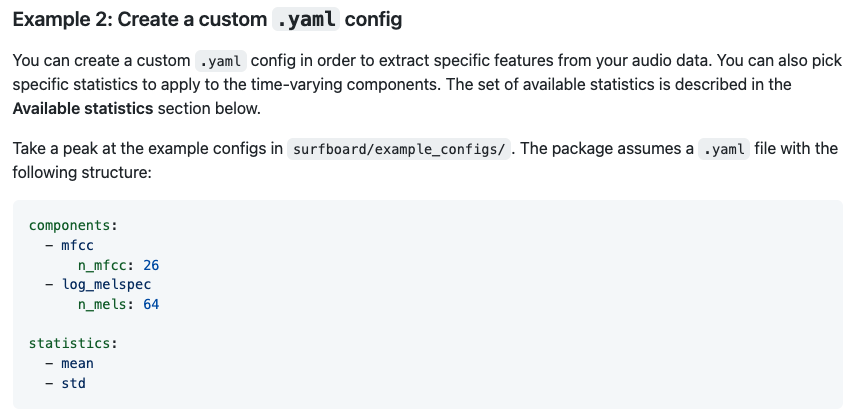
Surfboard는 이 다음 섹션부터 소개할 여러 사운드 라이브러리를 사용하기 쉽게 감싸놓은 (Wrapping) 해 놓은 라이브러리이다. 복잡하게 저수준의 함수를 직접 사용하는 대신, yaml파일에 기록하면 관련된 음성 Feature를 자동을 추출할 수 있다. 라이브러리를 사용하는 방법은 다양하다.
- Python Code에서 Import 하여 직접 사용하는 방법
- wav 파일들이 존재하는 폴더만 지정하여 csv/pkl 파일로 추출하는 방법
- yaml 파일로 커스텀 설정하여 사용하는 방법
- 제공되는 notebook_tutorials를 사용하는 방법
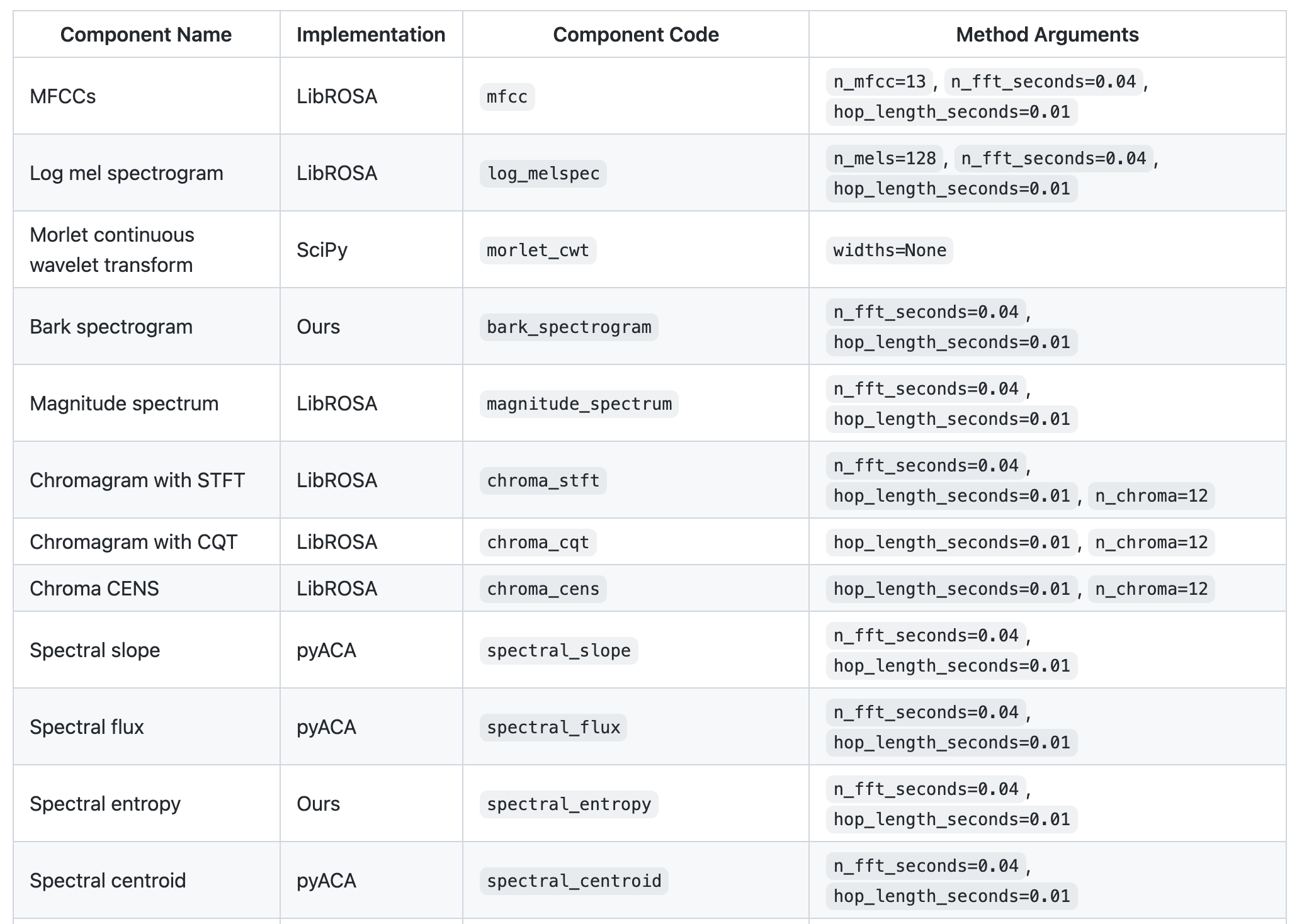
아래와 같이 수많은 Feature 추출을 간편하게 수행할 수 있다.
2. LibRosa

audio 파일을 다루거나 signal processing을 할 때, 가장 쉬울 뿐만 아니라 강력한 라이브러리 이다. librosa.load() 함수 하나로 wav파일을 읽어 들일 수 있다. 상세하게는 sampling rate 조절, resampling등을 다양한 기능을 제공한다.
import librosa
x, sr = librosa.load('audio/simple_loop.wav')단순하게 audio 파일을 읽고 쓰는것 외에도, 다양한 STFT, Spectogram, MFCC, Display등 다양한 기능을 제공하여, 저수준에서 고수준 기능까지 전반적으로 통합되어 있는 라이브러리이다. 또한, Decomposition, Detection 등 다양한 Application에 대한 예제를 제공하며, 많은 사용자 층이 있어서 인터넷에 관련 자료를 찾기 쉽다.
waveplot
matplotlib.pyplot.plot()으로 출력하면 되긴 하지만, 이것 저것 설정하는것이 귀찮다면, waveplot으로 wave의 파형을 볼 출력해 볼 수 있다.
import matplotlib.pyplot as plt
import librosa.display
plt.figure(figsize=(14, 5))
librosa.display.waveplot(x, sr=sr)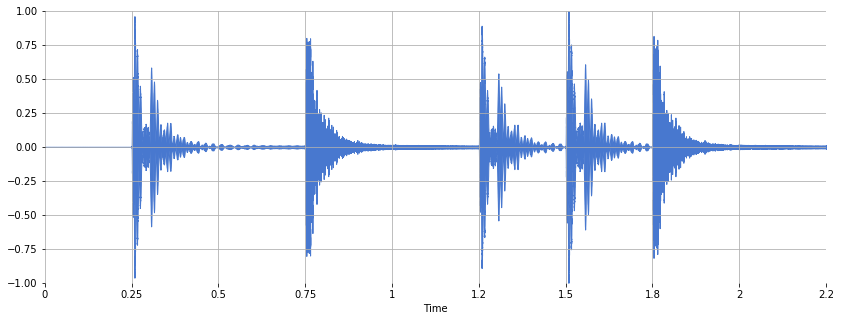
FFT 변환
음성 및 시계열 신호를 다루다 보면 필연적으로 맞이하게 되는 것이, Frequency Domain으로 변환이다. FTT를 짧은 Frame 단위로 구해주는 STFT (Short Time Fourier Transform)을 기본 내장하고 있다.
X = librosa.stft(x)
Xdb = librosa.amplitude_to_db(abs(X))
plt.figure(figsize=(14, 5))
librosa.display.specshow(Xdb, sr=sr, x_axis='time', y_axis='hz')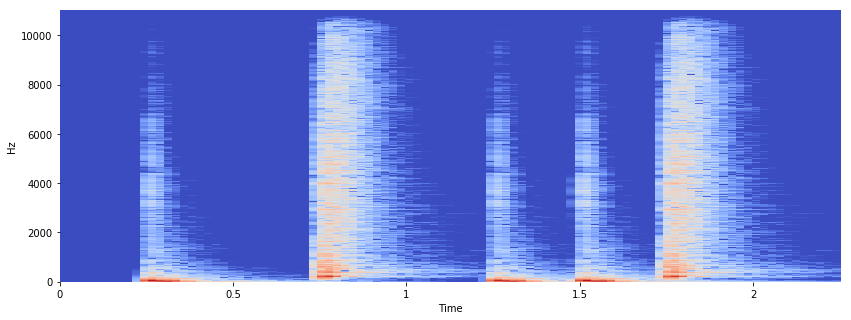
Specshow()
변환된 Spectrum, Spectogram은 변경 후에 이미지로 출력해서 볼 필요가 있다. 이 때 기존 이미징 도구들 (imshow(), image() 등)과는 x,y축 및 스케일 등의 설정에서 매우 번거로운 작업을 수반한다. librosa에서는 specrum 전용의 이미지 출력 함수를 지원한다.
import matplotlib.pyplot as plt
y, sr = librosa.load(librosa.ex('choice'), duration=15)
fig, ax = plt.subplots(nrows=2, ncols=1, sharex=True)
D = librosa.amplitude_to_db(np.abs(librosa.stft(y)), ref=np.max)
img = librosa.display.specshow(D, y_axis='linear', x_axis='time',
sr=sr, ax=ax[0])
ax[0].set(title='Linear-frequency power spectrogram')
ax[0].label_outer()hop_length = 1024
D = librosa.amplitude_to_db(np.abs(librosa.stft(y, hop_length=hop_length)),
ref=np.max)
librosa.display.specshow(D, y_axis='log', sr=sr, hop_length=hop_length,
x_axis='time', ax=ax[1])
ax[1].set(title='Log-frequency power spectrogram')
ax[1].label_outer()
fig.colorbar(img, ax=ax, format="%+2.f dB")
FFT/STFT 의 변화 결과는 복소수 (Complex)로 반환된다. 이 때, 복소수(Complex Number)에서 실제 신호의 크기 (Magnitude)를 구하기 위해서 `np.abs(librosa.stft(y))` 를 사용한다. 또한, Sound의 세기는 amplitude 자체보다 데시벨(dB)로 처리되므로, Amplitude (magnitude) --> 데시벨로 변환한다. : `amplitude_to_db()`
위의 스펙트로그램에서 2번째 이미지는 y축을 `log scale`로 변환한 그림이다. 사람이 소리를 듣는데에 High Frequency로 갈 수록 상대적으로 약하게 듣고, 넓은 Frequecy를 축약해서 듣는 경향이 있으므로 Log-Scale로 분석하는 경우가 많기 때문이다. 이 것을 좀 더 반영한 `LogMel Spectrogram`이 별도로 존재한다.
Librosa에서 파일 Write는 어떻게 할 것인가?
Librosa의 이전 버전 (0.7 이하)에서는, `librosa.output` 등에서 writefile을 지원 했었다. 그러나, 버전업이 되면서 이러한 부분들이 사라졌다. librosa는 내부적으로 soundfile을 사용하고 있는데, writefile의 경우 별다른 wraping 보다는 soundfile을 직접 사용하는 것이 관리/안정적이라고 판단 한듯 하다. 따라서, librosa로 다루는 wav/pcm/mp3 등의 신호를 파일로 쓸 때는 다음 섹션에서 소개하는 soundfile을 사용하면 된다.
3. Soundfile
wav 파일 외에, RAW 파일 등 사운드 파일 Structure를 파일, 오브젝트 형태로 읽거나 쓰는데 특화 되어 있다. 파일/Serialize 레벨에서 wav를 처리할 때 좋다. 다만, 파일의 신호단위에서 가공/처리하는 함수들은 지원하지 않는다. Librosa 등 고수준의 라이브러리들이 sound file을 읽거나 쓰기를 할 때 내부적으로 사용한다.
import soundfile as sf
data, samplerate = sf.read('existing_file.wav')
sf.write('new_file.flac', data, samplerate)
soundfile에서 파일 읽기 및 제어
import soundfile as sf
with sf.SoundFile('myfile.wav', 'r+') as f:
while f.tell() < f.frames:
pos = f.tell()
data = f.read(1024)
f.seek(pos)
f.write(data*2)
soundfile에서 음원파일을 생성/쓰기 하는 예
import numpy as np
import soundfile as sf
rate = 44100
data = np.random.uniform(-1, 1, size=(rate * 10, 2))
# Write out audio as 24bit PCM WAV
sf.write('stereo_file.wav', data, samplerate, subtype='PCM_24')
# Write out audio as 24bit Flac
sf.write('stereo_file.flac', data, samplerate, format='flac', subtype='PCM_24')
# Write out audio as 16bit OGG
sf.write('stereo_file.ogg', data, samplerate, format='ogg', subtype='vorbis')
4. ParselMouth
음성 신호 가공 라이브러인 Praat를 Python에서 사용할 수 있는 라이브러리 이다. 기존에 praat를 사용하는 유저라면 가장 선호되는 라이브러리라 할 수 있겠다. 음성신호를 읽고, 쓰고, 변환하여 시각화 하는데 매우 유용하다
import parselmouth
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set() # Use seaborn's default style to make attractive graphs
plt.rcParams['figure.dpi'] = 100 # Show nicely large images in this notebook
snd = parselmouth.Sound("audio/the_north_wind_and_the_sun.wav")
intensity = snd.to_intensity()
spectrogram = snd.to_spectrogram()
plt.figure()
draw_spectrogram(spectrogram)
plt.twinx()
draw_intensity(intensity)
plt.xlim([snd.xmin, snd.xmax])
plt.show()
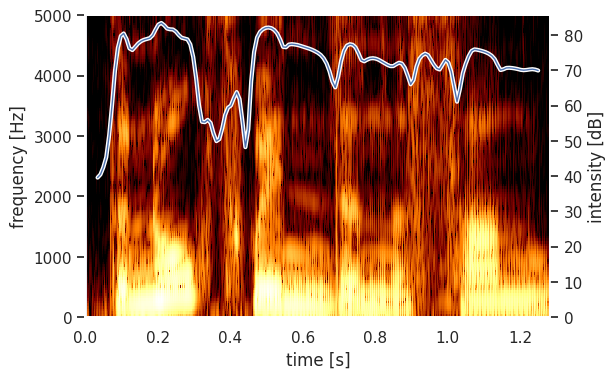
ParselMouth 또한 Sound를 처리함에 있어서 저수준 함수에서 고수준 함수까지 다양한 기능을 제공 한다. 그러나 아무래도 librosa 등과 비교하여, 범용성은 다소 낮다할 수 있다. 다만, ParselMouth의 가장 큰 장점이 있는데, 이는 바로, `praat`명령어를 실행할 수 있다는 점 이다. 다음은 praat 명령어 "To manipulation"을 실행하는 코드이다.
from parselmouth.praat import call
manipulation = call(sound, "To Manipulation", 0.01, 75, 600)기존에 praat를 사용해 온 유저의 경우는 당연하게도 parselmouth를 가장 사용이 용이할 것이다.
5. OpenSmile
음성관련 의학 논문에서 많이 사용되는 라이브러리 이다.
음성파일에 대한 Read/Write를 저수준으로 처리할 수 있을 뿐만 아니라, Sound에 관련된 일반적을 신호처리, 리샘플링, Feature Set가 사전정의 되어 있고 이를 추출하기 쉽다. (F0, Loudness, F1,F2,F3,F4, MFCC, Jitter, shimmer, HNR, slope, spectralFlux) 등을 Feature set으로 사전 정의해 두었으며, 이에 대한 통계값을 추출하기 쉽다. 이러한 이유로 Feature Set을 사용할 때 편리하여, 전자/컴퓨터 분야 외의 종사자들이 많이 사용하는것으로 보인다.
smile = opensmile.Smile(
feature_set=opensmile.FeatureSet.eGeMAPSv02,
feature_level=opensmile.FeatureLevel.Functionals,
)
smile.feature_names
다음은 opensmile에 사전 정의된 (predefined) 음성 특성변수 (Feature) 들이다.
['F0semitoneFrom27.5Hz_sma3nz_amean',
'F0semitoneFrom27.5Hz_sma3nz_stddevNorm',
'F0semitoneFrom27.5Hz_sma3nz_percentile20.0',
'F0semitoneFrom27.5Hz_sma3nz_percentile50.0',
'F0semitoneFrom27.5Hz_sma3nz_percentile80.0',
'F0semitoneFrom27.5Hz_sma3nz_pctlrange0-2',
'F0semitoneFrom27.5Hz_sma3nz_meanRisingSlope',
'F0semitoneFrom27.5Hz_sma3nz_stddevRisingSlope',
'F0semitoneFrom27.5Hz_sma3nz_meanFallingSlope',
'F0semitoneFrom27.5Hz_sma3nz_stddevFallingSlope',
'loudness_sma3_amean',
'loudness_sma3_stddevNorm',
'loudness_sma3_percentile20.0',
'loudness_sma3_percentile50.0',
'loudness_sma3_percentile80.0',
'loudness_sma3_pctlrange0-2',
'loudness_sma3_meanRisingSlope',
'loudness_sma3_stddevRisingSlope',
'loudness_sma3_meanFallingSlope',
'loudness_sma3_stddevFallingSlope',
'spectralFlux_sma3_amean',
'spectralFlux_sma3_stddevNorm',
'mfcc1_sma3_amean',
'mfcc1_sma3_stddevNorm',
'mfcc2_sma3_amean',
'mfcc2_sma3_stddevNorm',
'mfcc3_sma3_amean',
'mfcc3_sma3_stddevNorm',
'mfcc4_sma3_amean',
'mfcc4_sma3_stddevNorm',
'jitterLocal_sma3nz_amean',
'jitterLocal_sma3nz_stddevNorm',
'shimmerLocaldB_sma3nz_amean',
'shimmerLocaldB_sma3nz_stddevNorm',
'HNRdBACF_sma3nz_amean',
'HNRdBACF_sma3nz_stddevNorm',
'logRelF0-H1-H2_sma3nz_amean',
'logRelF0-H1-H2_sma3nz_stddevNorm',
'logRelF0-H1-A3_sma3nz_amean',
'logRelF0-H1-A3_sma3nz_stddevNorm',
'F1frequency_sma3nz_amean',
'F1frequency_sma3nz_stddevNorm',
'F1bandwidth_sma3nz_amean',
'F1bandwidth_sma3nz_stddevNorm',
'F1amplitudeLogRelF0_sma3nz_amean',
'F1amplitudeLogRelF0_sma3nz_stddevNorm',
'F2frequency_sma3nz_amean',
'F2frequency_sma3nz_stddevNorm',
'F2bandwidth_sma3nz_amean',
'F2bandwidth_sma3nz_stddevNorm',
'F2amplitudeLogRelF0_sma3nz_amean',
'F2amplitudeLogRelF0_sma3nz_stddevNorm',
'F3frequency_sma3nz_amean',
'F3frequency_sma3nz_stddevNorm',
'F3bandwidth_sma3nz_amean',
'F3bandwidth_sma3nz_stddevNorm',
'F3amplitudeLogRelF0_sma3nz_amean',
'F3amplitudeLogRelF0_sma3nz_stddevNorm',
'alphaRatioV_sma3nz_amean',
'alphaRatioV_sma3nz_stddevNorm',
'hammarbergIndexV_sma3nz_amean',
'hammarbergIndexV_sma3nz_stddevNorm',
'slopeV0-500_sma3nz_amean',
'slopeV0-500_sma3nz_stddevNorm',
'slopeV500-1500_sma3nz_amean',
'slopeV500-1500_sma3nz_stddevNorm',
'spectralFluxV_sma3nz_amean',
'spectralFluxV_sma3nz_stddevNorm',
'mfcc1V_sma3nz_amean',
'mfcc1V_sma3nz_stddevNorm',
'mfcc2V_sma3nz_amean',
'mfcc2V_sma3nz_stddevNorm',
'mfcc3V_sma3nz_amean',
'mfcc3V_sma3nz_stddevNorm',
'mfcc4V_sma3nz_amean',
'mfcc4V_sma3nz_stddevNorm',
'alphaRatioUV_sma3nz_amean',
'hammarbergIndexUV_sma3nz_amean',
'slopeUV0-500_sma3nz_amean',
'slopeUV500-1500_sma3nz_amean',
'spectralFluxUV_sma3nz_amean',
'loudnessPeaksPerSec',
'VoicedSegmentsPerSec',
'MeanVoicedSegmentLengthSec',
'StddevVoicedSegmentLengthSec',
'MeanUnvoicedSegmentLength',
'StddevUnvoicedSegmentLength',
'equivalentSoundLevel_dBp']
[추가] Scipy.io. wavfile
위 Audio 라이브러리들이 없다면, 음성파일을 읽지 못하는 것일까?
당연히 아니다. 직접 파일로 읽어들일 수도 있겠지만, scipy.io에는 다양한 파일에 대한 로딩/디코딩을 지원한다. 다음과 같이 scipy.io.wavfile에 "read"함수를 통해서 wav 파일을 로딩 할 수 있다.
[ READ]
from scipy.io import wavfile
wav_fname ='gettysburg.wav'
samplerate, data = wavfile.read(wav_fname)
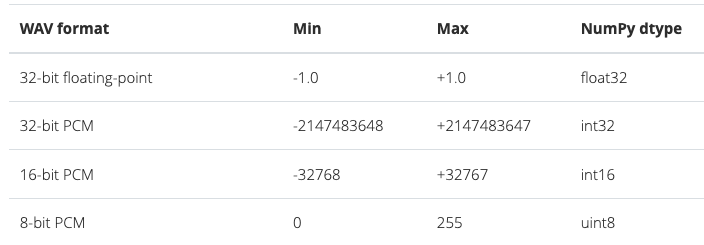
print(f' - rate: {samplerate} , data shape : {data.shape}')scipy.io.wavfile로 로딩된 wav/PCM은 데이터가 정수(int)로 표현된다. librosa 등 다른 라이브러리가 float로 표현하는 것과 다소 차이가 있으므로 normalization 관점에서 scale에 유의해야 할 것이다.
당연히 이렇게 읽은 데이터는 IPython.display.Audio를 통해서 출력이 가능하다.
import IPython.display as ipd
ipd.Audio(data,rate=samplerate)array로 된 데이터는 samplerate 정보가 없기 때문에, `rate=samplerate`로 입력해서 samplerate를 명시적으로 지정해 주어야 한다.
[ Write ]
array로 메모리에 읽어들인 데이트는 `scipy.io.wavfile`의 write()를 이용해서 PCM/wav 형태로 저장할 수 있다. 의외로 READ는 많은 방법이 공유 되어 있으나, Write 방법은 많이 알려져 있지 않다.
from scipy.io.wavfile import write
import numpy as np
write("example.wav", samplerate, data.astype(np.int16))Write할 때는 PCM의 bit 수에 따른 포맷을 명시할 필요가 있다. 다음은 타입별 wav format 이므로 참조하기 바란다.